Benchmarking Visual Programming in XLogoOnline
This project was conducted in collaboration with Jacqueline Staub (University of Trier) and Adish Singla (MPI-SWS).
TL;DR
This project introduces a visual programming benchmark to assess the ability of large models (e.g., GPT-4o, DeepSeek-R1) to synthesize code that solves visual programming tasks.
Introduction
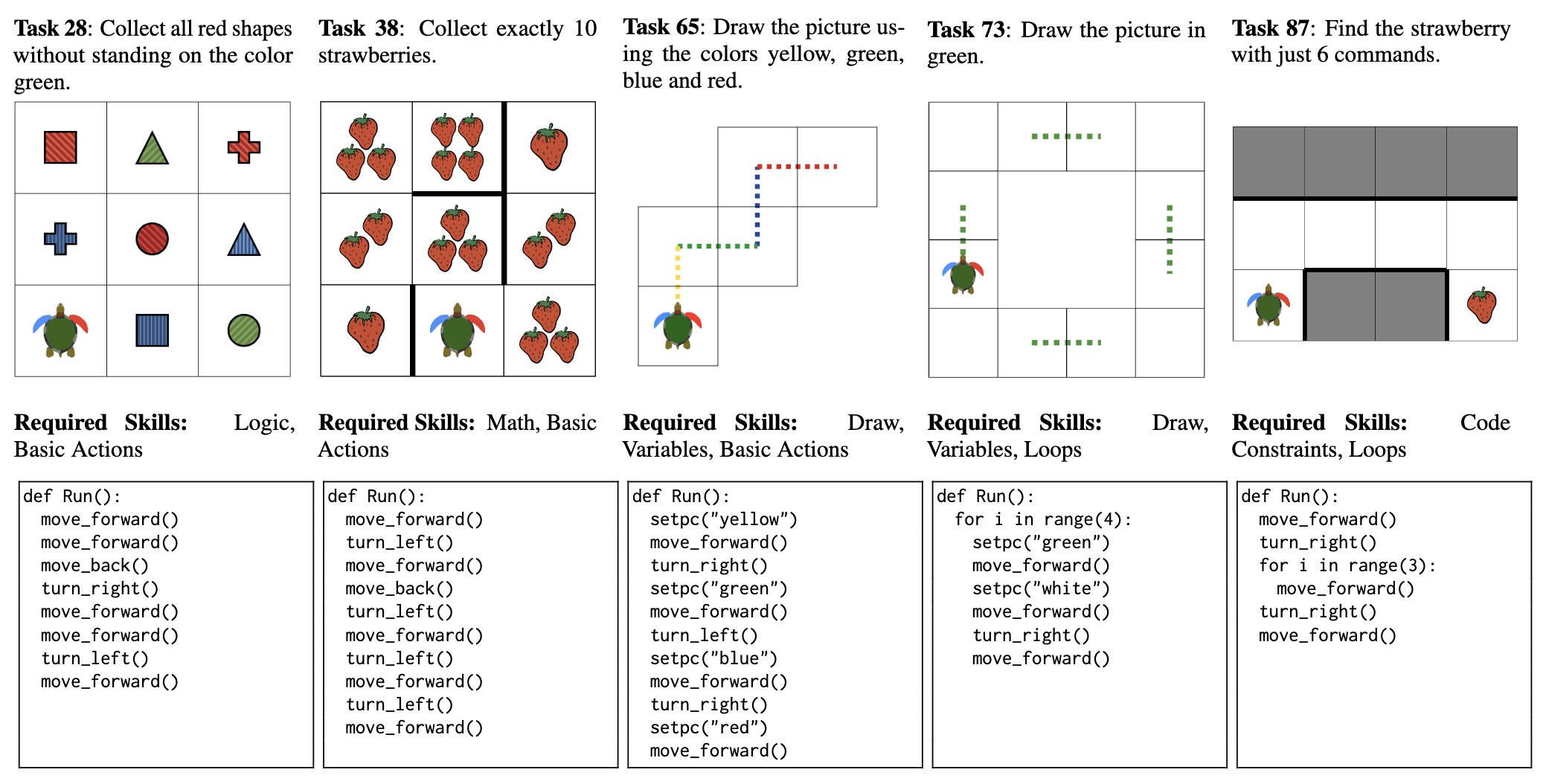
Visual programming environments like XLogoOnline are widely used in education to teach fundamental programming concepts through interactive, grid-based tasks. Unlike standard code generation or math benchmarks, real-world visual programming tasks demand a blend of skills—spatial planning, arithmetic, logic, and code constraints. This project addresses the gap in existing benchmarks by introducing XLOGOMINIPROG: a suite of 85 real-world and 1,000 synthetic tasks from XLogoOnline-Mini, each requiring models to synthesize code that directs a turtle to achieve a specified goal in a visual grid world.
- XLOGOMINIPROG is a program synthesis benchmark for visual programming tasks.
- XLOGOMINIPROG is built on top of the visual programming platform XLogoOnline.
Key Takeaways
- The benchmark evaluates how well large models can solve these tasks, how their abilities vary across different skill dimensions, and how targeted fine-tuning can boost their performance.
Key Results

How Do LMs Perform?
- XLOGOMINIPROG is challenging for LMs, but easy for humans
- Vision capabilities provide limited benefits, while reasoning capabilities are crucial
- Fine-tuning is useful; adjusting training data distribution can improve fine-tuning performance
Why do LMs fail?
- GPT-4V and Llama3-70B fail most tasks due to spatial reasoning
- DeepSeek-R1-Distill-Llama-70B fails most tasks due to recursive reasoning
- Fine-tuned models fail most tasks due to grid constraints
Links
- Paper: https://arxiv.org/pdf/2406.11334
- Code & Benchmark: https://github.com/machine-teaching-group/acl2025-xlogominiprog